A Chrome Extension for Local Transcription Processing
/ 2 min read
Table of Contents
This YouTube video is licensed under CC BY.
Motivation
While many transcription tools exist, most require uploading audio files to the cloud for processing. Due to security compliance, I’ve often encountered situations where uploading recorded audio to external servers isn’t permissible. Tools like Siri and the Web Speech API are tailored for transcribing one’s own voice and aren’t suitable for meetings or conversations involving multiple speakers. Moreover, the Web Speech API sends audio data to Google, and its data usage policy isn’t clearly defined. (If anyone knows where this is documented, please let me know: Google Privacy Policy.)
To address this, I decided to run a Whisper model locally using huggingface/transformers.js for transcription. I developed a Chrome extension called chrome-extension-web-transcriptor-ai. By utilizing the tabCapture API, capturing audio playing within a tab becomes straightforward. This approach allows for secure transcription entirely on the local machine without any network communication aside from the initial model download, ensuring that audio data isn’t uploaded to external servers.
Challenges Faced
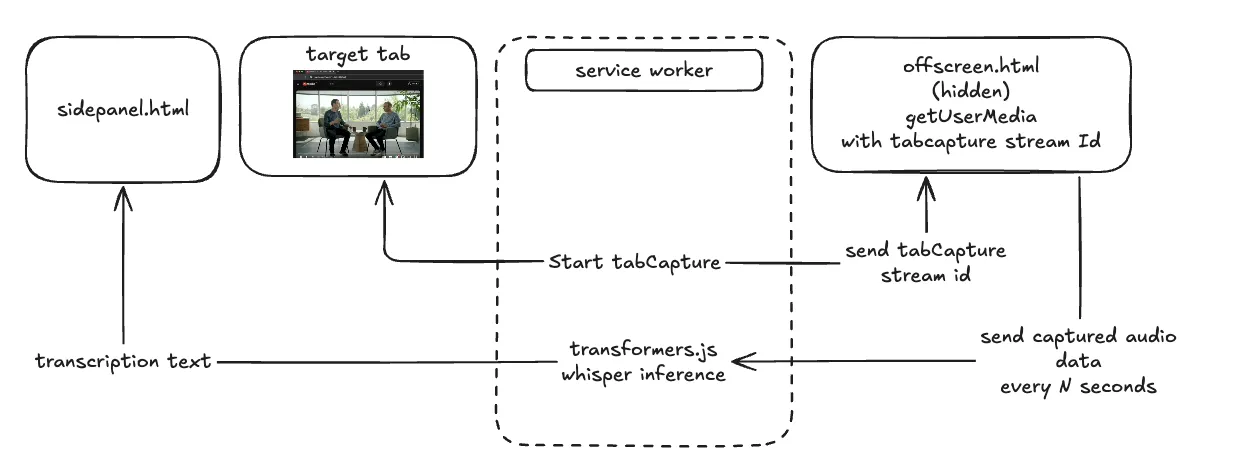
Initially, I wanted to use the Web Speech API for transcription but found no interface to specify input sources—it seems to accept audio only from input devices like microphones. Since I couldn’t feed the tabCapture audio into the Web Speech API, I pivoted to using transformers.js. I plan to dive into the Web Speech API’s implementation when I have time to confirm this limitation.
Another significant hurdle was that chrome.runtime.sendMessage can only transmit serializable objects. I struggled with passing audio data because Float32Array isn’t serializable. Without realizing this, I initially tried to pass it directly, which didn’t work. I ended up converting the Float32Array to a string using JSON.stringify, but this approach isn’t efficient. I’m looking into better serialization methods to improve performance.
Conclusion
I’m using the onnx-community/whisper-large-v3-turbo model for Whisper. Testing so far has been on a MacBook Pro with an M2 Pro chip (32GB Memory), and it’s capable of high-precision transcription in multiple languages. It’s impressive that such a powerful model can now run on local devices.
With transformers.js, it’s possible to run not just Whisper but also large language models (LLMs). I’m considering adding a feature to summarize transcribed content using LLMs. For subsequent processing, integrating with tools like Gemini in Chrome could be beneficial.
While the model download does involve network communication, I’m thinking about implementing a feature to allow downloads from trusted servers to enhance security.